argopandas
![]()
![]()
![]()
The goal of argopandas is to provide seamless access to Argo NetCDF
files using a pandas DataFrame-based interface. It is a Python port
of the argodata package for
R. The package is under
heavy development and we would love feedback on the interface or
anything else about the package!
Installation
You can install the argopandas package using pip.
pip install argopandas
The package depends on pandas, numpy, netCDF4, and
pyarrow, which install automatically if using pip or you can
install also your favourite Python package manager. The argopandas
package requires Python 3.6 or later.
Examples
The intended interface for most usage is contained in the argopandas
module. You can import this as argo for pretty-looking syntax:
import argopandas as argo
The global indexes are available via argo.prof, argo.meta,
argo.tech, argo.traj, argo.bio_prof,
argo.synthetic_prof, and argo.bio_traj.
argo.meta.head(5)
file profiler_type institution date_update
0 aoml/13857/13857_meta.nc 845 AO 20181011200014
1 aoml/13858/13858_meta.nc 845 AO 20181011200015
2 aoml/13859/13859_meta.nc 845 AO 20181011200025
3 aoml/15819/15819_meta.nc 845 AO 20181011200016
4 aoml/15820/15820_meta.nc 845 AO 20181011200018
By defaut, downloads are lazily cached from the Ifremer https
mirror. You can use
argo.url_mirror() or argo.file_mirror() with
argo.set_default_mirror() to point argopandas at your favourite
copy of Argo.
To get Argo data from one or more NetCDF files, subset the indexes and
use one of the table accessors to download, cache, and read variables
aligned along common dimensions. The accessor you probably want is the
.levels accessor from the argo.prof index:
argo.prof.head(5).levels[['PRES', 'TEMP']]
PRES TEMP
file N_PROF N_LEVELS
aoml/13857/profiles/R13857_001.nc 0 0 11.900000 22.235001
1 17.000000 21.987000
2 22.100000 21.891001
3 27.200001 21.812000
4 32.299999 21.632000
... ... ...
aoml/13857/profiles/R13857_005.nc 0 102 976.500000 4.527000
103 986.700012 4.527000
104 996.799988 4.533000
105 1007.000000 4.487000
106 1017.200012 4.471000
[551 rows x 2 columns]
You can get data from every variable in an Argo NetCDF file using one of these accessors. The variables grouped in each are aligned along the same dimensions and are documented together in the Argo user’s manual.
All indexes have a
.infoaccessor that contains length-one variables that aren’t aligned along any dimensionsargo.prof:argo.prof.levels,arog.prof.prof,argo.prof.calib,argo.prof.param, andargo.prof.historyargo.traj:argo.traj.cycle,argo.traj.measurement,argo.traj.param, andargo.traj.historyargo.tech:argo.tech.tech_paramargo.meta:argo.meta.config_param,argo.meta.missions,argo.meta.trans_system,argo.meta.positioning_system,argo.meta.launch_config_param,argo.meta.sensor, andargo.meta.param
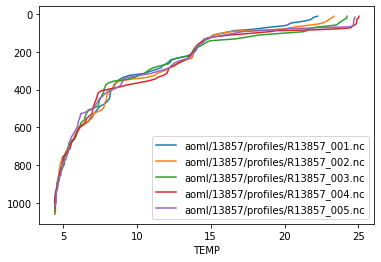
Once you have a data frame you do anything you’d do with a regular
pd.DataFrame(), like plot your data using the built-in plot method:
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
for label, df in argo.prof.head(5).levels.groupby('file'):
df.plot(x='TEMP', y = 'PRES', ax=ax, label=label)
ax.invert_yaxis()
You can access all the index files for a particular float using
argo.float(), which lazily filters all the indexes for a particular
float ID.
float_obj = argo.float(13857)
float_obj.meta.info
Reading 1 file
DATA_TYPE FORMAT_VERSION HANDBOOK_VERSION file
aoml/13857/13857_meta.nc 0 Argo meta-data 3.1 1.2
DATE_CREATION DATE_UPDATE PLATFORM_NUMBER file
aoml/13857/13857_meta.nc 0 20181011200014 20181011200014 13857
PTT file
aoml/13857/13857_meta.nc 0 09335 ...
PLATFORM_FAMILY file
aoml/13857/13857_meta.nc 0 FLOAT ...
PLATFORM_TYPE file
aoml/13857/13857_meta.nc 0 PALACE
PLATFORM_MAKER file
aoml/13857/13857_meta.nc 0 WRC ...
... LAUNCH_QC START_DATE START_DATE_QC file ...
aoml/13857/13857_meta.nc 0 ... b'1' 19970719163000 b'1'
STARTUP_DATE STARTUP_DATE_QC file
aoml/13857/13857_meta.nc 0 19970719103000 b'1'
DEPLOYMENT_PLATFORM file
aoml/13857/13857_meta.nc 0 R/V Seward Johnson
DEPLOYMENT_CRUISE_ID file
aoml/13857/13857_meta.nc 0 97-03
DEPLOYMENT_REFERENCE_STATION_ID file
aoml/13857/13857_meta.nc 0 CTD 108 ...
END_MISSION_DATE END_MISSION_STATUS
file
aoml/13857/13857_meta.nc 0 NaN
[1 rows x 43 columns]